Hallo Leute,
besteht auch die Möglichkeit bei einem Film, bei dem der Ton mit ogg bearbeitet wurde, den Ton lauter zu bekommen????
Alles, was ich im Form gefunden habe, bezog sich auf avis.
Danke Sunrise

Hallo Leute,
besteht auch die Möglichkeit bei einem Film, bei dem der Ton mit ogg bearbeitet wurde, den Ton lauter zu bekommen????
Alles, was ich im Form gefunden habe, bezog sich auf avis.
Danke Sunrise
:google: "VorbisGain" - sollte helfen! ![]()
Unter Umständen auch vorher aus dem OGM Audio demuxen, verstärken, zurückmuxen.
Danke LigH,
nur wo finde ich das Teil..... hier bei doom9 wohl nicht?
Ich hoffe ich werde nicht zu lästig
Thanks Sunrise
Hast recht - da kommen erstmal nur viele Quelltext-Seiten... Aber mit der Suche nach "vorbisgain win32" kriegt man ein paar Seiten mit Versionen, die für Windows compiliert wurden. Zum Beispiel auf der Seite von Sjeng, der auch mal eine recht bekannte Freeware-Schach-Engine geschrieben hatte:
http://sjeng.org/vorbisgain.html
Ansonsten kannst du auch immer noch bei http://www.vorbis.com bzw. http://www.xiph.org nach Software suchen.
Ich frag mich grad, warum man nicht gleich bei der AC3-Ogg-Konvertierung nen Gain angibt? Ist doch viel einfacher, als dieses ganze Rummu(r)xen mit dem Eselkrempel ![]()
Belle die weit entfernten Huftiere nicht so laut an, sonst kriegst du von Micha eins auf die Nase! ;D
Klar Schnuffix, das ist einfacher ....
Aber wie geht das ??? ![]()
Indem man BeSweet oder HeadAC3he benutzt, Normalisieren bei der Umwandlung verwendet, und entweder Dynamikkomprimierung im Azid-Decoder oder den Booster mittendrin. So wie schon seit Jahren dokumentiert (wenn auch eher für AC3 => MP3, aber AC3 => OGG ist doch technisch das selbe bis kurz vor der Auswahl des Ausgabeformates).
Viele Wege führen nach Rom, aber ich behaupte mal, eine Abkürzung zu haben, die ich empfehlen könnte :] :
- Erstmal mit DVD2AVI die jeweiligen Tonspuren zu decoden (in Wav), darauf achten, daß der eingebaute Normalizer aktiviert ist und auf 95% steht (bei 100% besteht die Gefahr einer Übersteuerung, besonders bei Filmexplosionen)
- Dann mit OggdropXP umwandeln > gewünschte Quality Settings auf 2 oder 4 (je nach Aktualität des Materials), resamplen auf 44.01
...
- Und dann beim Player darauf achten, das die Audiokonfiguration auf Direct Sound steht, damit ein anderes Programm, wie bpsw, Winamp die Lautstärke nicht vorher beeinflußt hat.
HeadAC3he würde ich nur empfehlen bei Musik... dafür ist es absolut ein Muß!!!
TschoÖ ![]()
also normaliesieren ist ein absolutes tabu in der audio kompressions szene (kenn mich da etwas aus) aus dem einfachen grund, das normalisieren zwar alles lauter macht, aber eben wirklich alles. beim normalisieren wird alles auf einheitliche lautstärke gebracht, also auch die im gesamtzusammenhang leiseren stellen, somit geht die dynamik innerhalb eines musikstücks oder der tonspur eines films verloren.
lösung: replaygain (vorbisgain), ist eine art verstärkungsinformation, die dem audio decoder sagt, das er das ganze einfach um +x.xx db verstärken oder um -x.xx db abschwächen soll, und zwar so, dass die spitzen auf 89db sind, somit wird auch sog. clipping (übersteuern) verhindert.
wie man das ganze macht und auch links findet man in meinem audio kompression guide auf https://localhost/www.digital-destiny.net.ms
hoffe ihr habt alles verstanden ![]()
gruss
darktemplar
Also ich versteh das nicht, denn: Da alles lauter gemacht wird, und zwar durch Multiplikation mit einem konstanten Faktor (normalerweise der Faktor, durch den danach die allerlauteste Stelle gerade eben 100% Aussteuerung erreicht), bleibt die Dynamik (also der Abstand zwischen leisen und lauten Stellen) - relativ gerechnet, also als Verhältnis - exakt gleich!
Simples Rechenbeispiel:
eine leise Stelle: 0.2
eine laute Stelle: 0.6
Dynamik für diese beiden Stellen: 0.6 : 0.2 = 3.
ein Verstärkungs-Faktor: 1.5
verstärkte leise Stelle: 0.2 * 1.5 = 0.3
verstärkte laute Stelle: 0.6 * 1.5 = 0.9
Dynamik für diese verstärkten Stellen: 0.9 : 0.3 = ... 3!
Oder hab ich das jetzt falsch verstanden?
__
Wobei Dynamik wirklich verlorengeht, ist Dynamikkomprimierung (wie der Name schon sagt): Da werden leise Stellen kräftig verstärkt, schon laute Stellen aber weniger stark. Dadurch verringert sich der Abstand zwischen Leise und Laut.
also ich kopier um das ganze klarzustellen einfach mal etwas aus einem englischen forum:
Normalization is a lossy process for adjusting the gain of an audio file. Anything it puts below the noise floor upon gaining down a track is lost. If you try gaining up the same track, you'll have forever lost the audio that originally existed between the pre-gain noise floor and the post-gain noise floor. Only noticable on a track with one or more *very* quiet passages, but more noticable if the normalization was fairly steep (greater than, say, 5 dB).
ReplayGain (or the MP3Gain variant) is lossless. It makes adjustments to the metadata inside the MP3 file (there's a better way of describing this part, I'm sure), but does not lose a single bit of actual audio data. Hence, if you gain down a track with ReplayGain, anything pushed below the noise floor still actually exists in the file. If the track is ever gained up again, that portion of the audio would be perfectly restored to its pre-gain state.
Therefore, IMHO, ReplayGain/MP3Gain is the better way for basic gain adjustment, at least for lossy encoding formats.
quelle: http://www.hydrogenaudio.org/index.php?show…80&hl=normalise
Ach, ich wußte doch, worauf die hinauswollen: Wenn das Ausgangsmaterial eine begrenzte Auflösung hat (z.B. 16 bit Integer), dann bringt Normalisierung erhebliche qualitative Einbußen. Aber nicht wegen der Technik der Normalisierung, sondern wegen der Quantisiertheit des Materials!
BeSweet und HeadAC3he jedoch verwenden Decoder, die Fließkommawerte erzeugen, und gerade AC3-Daten werden ja möglichst nach Fließkomma decodiert, eben weil sie so einen extremen Dynamikumfang haben.
_
Um die Unterschiede zwischen Integer- und Float-Samples zu verdeutlichen:
Integer-Samples haben eine maximale Auflösung - auf CD sind es 16 bit. Diese 16 bit werden aber nur in den allerlautesten Szenen ausgenutzt. Szenen, die nur halb so laut sind wie das Maximum, belegen nur noch 15 bit. Viertel Lautstärke - 14 bit... - Bei den allerleisesten Szenen kann es dadurch passieren, dass nur noch wenige Bits und dadurch sehr wenig verschiedene Werte über einen Klang entscheiden: Das "Quantisierungsrauschen" (Noise Floor) nimmt Überhand. In Grenzen kann es durch Dithering und Noise Shaping noch ausgenutzt werden, um psycholakustisch noch "Zwischenlautstärken" zu simulieren.
Anders Fließkomma-Samples: IEEE-Single-Precision-Werte haben 24 bit Mantisse und 8 bit Exponent. Der 8-bit-Exponent repräsentiert dabei die Position des höchstwertigen 1-Bits und dadurch die "Größenordnung" der Lautstärke, die 24 bit Mantisse dagegen die gültigen Bits nach dem höchstwertigen 1-Bit - das bedeutet: Egal bei welcher Lautstärke, jedes Sample hat (bis zu) 25 bit Genauigkeit (begrenzt durch die Qualität der Vorlage und der Psychoakustik beim Komprimieren). Theoretisch wäre damit jedoch ein Dynamikumfang von tausenden Dezibel speicherbar.
Meßbare Qualitätsverluste treten somit sehr wahrscheinlich auf, wenn man Integer-Werte von mäßiger Auflösung (und 16 bit sind heutzutage eher wenig) mit Fließkommafaktoren multipliziert. Aber eine Multiplikation zweier Fließkommawerte verschlechtert die Genauigkeit nicht meßbar (theoretisch auf höchstens 1 bis 2 bit weniger als die kleinere der Auflösungen, also vielleicht auf 22 bit - selbst in den allerleisesten Szenen! Was für ein Unterschied zu 1 bis 4 bit bei Integer-Samples, wo das Quantisierungsrauschen dann deutlich Einfluss hätte).
kurzgesagt es schadet einer ac3 tonspur in keinster weise wenn ich sie normalisiere?
Wenn sie nicht zwischendurch als 16-Bit-Integer, sondern als Float decodiert wird (was BeSweet und HeadAC3he mit ihrer azid.dll-Version so tun), dann nicht.
Ich mach morgen mal noch zwei Grafiken, die das mit der Auflösung in beiden Fällen noch mal verdeutlichen...
interessante Ausführungen LigH!
Bin mal auf die Grafiken gespannt. Visualisiert ist es bestimmt noch besser verständlich.
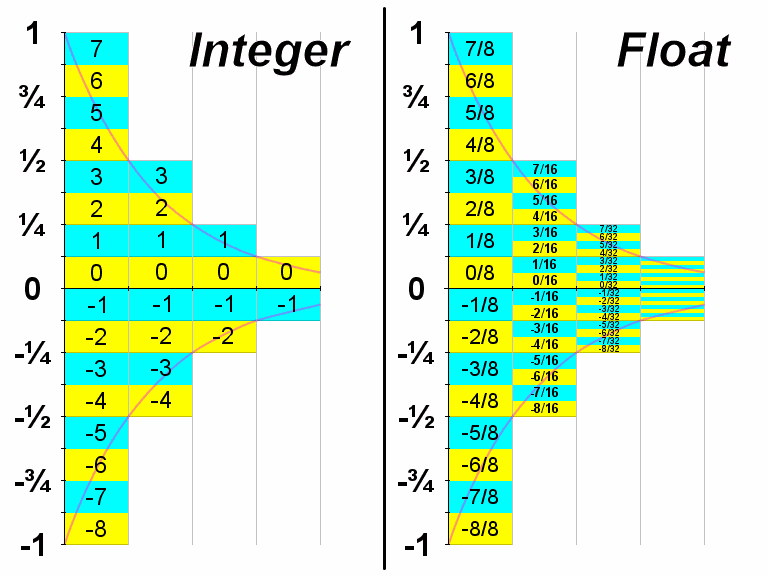
Was man nicht im Kopf hat... sollte man sich mal aufschreiben: Mit einer Woche Verspätung nun die Grafik!
[Blockierte Grafik: http://www.ligh.de/images/int~float.gif]
Zur Vereinfachung habe ich mal nur maximal 4 bit pro Sample angenommen - natürlich sind wesentlich mehr üblich, aber dann würde keiner mehr was erkennen...
Auf der linken Seite ist zu erkennen: Bei vollem Pegel hat man bis zu 4 bit / 16 verschiedene Werte zur Verfügung; bei halbem Pegel reduziert sich die Auflösung auf maximal 3 bit / 8 verschiedene Werte, und irgendwann hat man dann nur noch 1 bit (0 / -1) als einzigen Hinweis auf ein Vorzeichen, nicht mal mehr die Größenordnung ließe sich daraus rekonstruieren (das wäre dann der "Noise Floor", das Grundrauschen wegen der Quantisierung).
Auf der rechten Seite dagegen ist zu erkennen, dass bei Fließkommawerten unabhängig von der Größenordnung (voller / halber / viertel ... Pegel) der verwendete Bereich immer bis zu 4 bit / 16 Werte genau beschrieben werden kann. Als Bruch dargestellt, hat man immer gleich genaue Zähler, nur der Nenner ändert seine Größenordnung (um Faktor 2, weil ein Prozessor ja binär rechnet).
Sie haben noch kein Benutzerkonto auf unserer Seite? Registrieren Sie sich kostenlos und nehmen Sie an unserer Community teil!
{kind=link}